

Total-perspective-vortex
당신의 뇌를 쉘로! (뉄?)
by Jean Pirschm, jprisch@student.42.fr
Summary: 전기 뇌파 데이터(EEG Data)를 기반으로 한 Machine Learning과 Brain-Computer 인터페이스
Version: 2
Chapter I, Foreword

"Total Perspective Vortex는 추정된 물질 분석의 원리에 따라 전체 우주에 대한 그림을 도출합니다. 설명하자면 — 우주의 모든 물질은 어떤 식으로든 우주의 다른 모든 물질의 영향을 받기 때문에 이론상 모든 태양, 모든 행성, 궤도, 구성, 경제적, 사회적 역사 등 창조 전체를 작은 요정 케이크 한 조각에서(예를 들자면) 추정할 수 있습니다. Total Perspective Vortex를 발명한 사람은 기본적으로 다음과 같은 목적으로 그렇게 했습니다. 트린 트라굴라(Trin Tragula)는 몽상가, 사상가, 사변 철학자, 또는 백치(그의 아내의 표현대로)였습니다. 그리고 아내는 그가 엄청나게 많은 시간을 보냈다고 끊임없이 잔소리를 해댔죠. 우주를 응시하거나, 안전핀의 역학에 대해 숙고하거나, 요정 케이크 조각의 분광학적 분석을 수행합니다. 그녀는 가끔 하루에 서른여덟 번이나 말하곤 했습니다. 그래서 그는 아내에게 보여주는 것만을 위해 Total Perspective Vortex를 창조했습니다. 그리고 한쪽 끝에 그는 요정 케이크 조각에서 추정한 것처럼 현실 전체를 연결했습니다. 아내는 놀랍게도 그 충격으로 인해 뇌가 완전히 소멸되었지만, 결과 자체는 만족스러웠습니다. 그는 이 정도 크기의 우주에 생명체가 존재한다면 생명체가 가질 수 없는 단 한 가지는 비례감이라는 사실을 결정적으로 증명했다는 것을 깨달았습니다."
Douglas Adams, The Restaurant At The End Of The Universe
Chapter II, Introduction
이 과제는 Machine Learning 알고리즘의 도움을 받아 뇌파 데이터(EEG 데이터)를 기반으로 Brain-Computer Interface를 만드는 것을 목표로 합니다.
피험자의 EEG 판독값을 사용하여 에서 시간 범위까지의 움직임 A와 B에 대해 생각하거나 행동하는 것을 추론해야 합니다.
Chapter III, Goals
EEG 데이터 처리하기 (파싱, 필터링)
차원 감소 알고리즘 구현하기
Scikit-learn의 pipeline object 사용하기
"Real Time"으로 데이터 스트림 분류
Chapter IV, General Instructions
여러분은 머신러닝 알고리즘을 통해 대뇌 활동을 통해 얻은 데이터를 처리하게 될 겁니다.
데이터는 motor imagery experiment를 통해 측정되었습니다.
이 테스트는 사람들에게 화면의 특정 위치(랜덤하게)에 간단한 그림을 보여주고, 같은 방향에 해당하는 이 손/발 움직임에 대해 상상하거나 행동하도록 합니다.
결과물은 대상이 특정 작업을 수행해야 하는 순간을 나타내는 레이블이 있는 대뇌 신호입니다.
뇌파 데이터 처리에 특화된 라이브러리인 MNE와 Machine Learning에 특화된 라이브러리인 scikit-learn을 제공하므로 Python으로 코딩해야 합니다.
이 과제는 classification 이전에 필터링된 데이터를 추가로 변환하기 위해 차원 감소 알고리즘(dimensionality redunction algorithm)을 구현하는 데 중점을 둡니다.
classification 및 score validation을 위해 sklearn 도구를 사용할 수 있도록 sklearn 내에 통합되어야 합니다. (sklearn 사용 가능, pipeline은 필수)
+ classification을 직접 구현하는 것도 보너스가 될 수 있습니다. 보너스 페이지를 참고하세요.
Chapter V, Mandatory Part
3개의 데이터 처리 과정으로 구현된 python 프로그램을 작성하세요.
V.1 Preprocessing, parsing and formatting
첫번째입니다.
raw data를 시각화하는 스크립트를 작성한 다음 유용한 주파수 대역만 유지하도록 필터링하고 이 pre-processing 이후 다시 시각화해야 합니다.
이 부분은 signal을 알고리즘에 공급하기 위해 신호에서 추출할 기능을 결정하는 곳입니다.
따라서, 원하는 출력에 중요한 항목을 철저히 선택해야 합니다.
한 가지 예시로, 파이프라인의 입력에 대한 주파수 및 채널별로 신호의 전력을 사용할 수 있습니다.
신호의 유령을 필터링하고 얻는 것과 관련된 대부분의 알고리즘은 푸리에 변환 또는 웨이블릿 변환을 사용합니다. (보너스 페이지 참고)
V.2 Treatment Pipeline
위의 작업 이후 파이프라인을 처리해야 합니다.
•
차원 감소 알고리즘 (PCA, ICA, CSP, CSSP…)
www.kkim.info/my_project/dimensionality_reduction
•
Classification 알고리즘. sklearn에는 이와 관련된 선택지(알고리즘)들이 아주 많습니다.
어떤 데이터 청크가 어떤 종류의 움직임에 해당하는지에 대한 결정을 출력합니다.
•
“Playback” : 파일을 읽고 데이터 스트림을 해석하세요.
당신만의 CSP, 또는 어떠한 알고리즘이든 구현하기 전에 먼저 sklearn 및 MNE 알고리즘으로 프로그램 아키텍처를 테스트하는 것을 권장합니다.
이 프로그램은 학습을 위한 스크립트(training.py)와 예측을 위한 스크립트(predict.py)를 포함해야 합니다.
출력을 예측하는 스크립트는 데이터 청크가 처리 파이프라인으로 전송된 후 2초 지연 전에 데이터 스트림에서 이를 수행해야 합니다.
V.3 Implementation
목표는 차원 감소 알고리즘을 구현하는 것입니다.
이는 프로젝션 매트릭스를 결정하여 가장 의미 있는 특징으로 데이터를 표현하는 것을 의미합니다.
이 매트릭스는 가장 "중요한" 변화를 나타내는 새로운 축 세트에 데이터를 투사합니다.
이를 change of basis라고 하며 회전, 병진, 크기 조정 작업으로 구성된 변환입니다.
따라서 PCA는 데이터 세트를 고려하고 해당 축이 데이터의 변동을 설명하는 정도에 따라 정렬된 새로운 기본 구성 요소를 결정합니다.
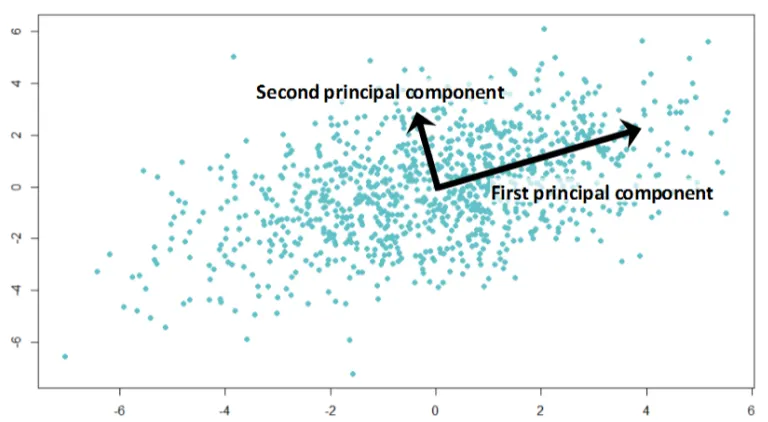
CSP 또는 공통 공간 패턴은 출력 클래스에 따라 데이터를 분석하고 변동을 최대화하려고 합니다.
PCA는 더 일반적인 알고리즘이지만, CSP는 EEG BCIs에서 더 많이 사용됩니다.
EEG 신호의 공식적인 표현을 살펴보겠습니다.
잠깐! 겁먹지 마세요. 하나하나 살펴봅시다.
•
: 모든 클래스의 이벤트 수
•
: 채널의 수(electrodes)
•
: 이벤트 레코딩의 길이
•
: 실수(Real number)의 집합
추출된 행렬 을 고려하면, 이 이벤트 레코드에 대한 신호 벡터의 차원임을 알고 있습니다.
여러분의 목표는 여기서 변환 행렬 를 찾는 거에요.
, 여기서 는 CSP 알고리즘에 의해 변환된 데이터를 의미합니다.
- 는 행렬 의 Transpose를 의미합니다. 대충 나무위키 링크
- CSP가 아닌 다른 차원 감소 알고리즘(XP, CA, XICA, … 등등)도 가능합니다.
이건 여러분의 선택!
고유값, 특이값 및 공분산 행렬 추정을 찾기 위해 Numpy 또는 scipy 함수도 허용됩니다.
Chapter VI, Bonus Part
보너스는 서브젝트를 진화시키는 어떠한 방법이든 허용됩니다.
•
signal spector variation을 통한 전처리 개선 (ex: wavelets 변형 사용하기).
•
자체 classification이나 파이프라인의 또 다른 단계 등 구현하기
•
또 다른 데이터셋 사용하기
파이프라인의 다른 부분을 구현함으로써 구문분석, 전처리, classification 등을 더 깊이 파고들 수 있습니다.
더 어려운 보너스는 고유값 함수 | 특이값 분해, 또는 공분산 행렬 추정(이 작업은 데이터가 노이즈의 영향을 받고, 정사각형 행렬을 형성하지 않기 때문에 더욱 어렵습니다.) 등이 있습니다.