제 2고지: 자연스러운 코드로!
가변 길이 인수: 순전파
지금까지 저희가 만든 연산들은 1개의 입력에 한개의 출력만 받고 있었습니다.
그러나 여러개의 입력, 여러개의 출력을 받는 함수들도 존재합니다.
그러므로 이를 적용하기 위해 코드를 수정해 봅시다.
# class: Function
class Function:
def __call__(self, _input_list):
x_list = [x._data for x in _input_list]
y_list = self.forward(x_list)
output_list = [Variable(as_array(y)) for y in y_list]
for output in output_list:
output.set_creator(self)
self._input_list = _input_list
self._output_list = output_list
return output_list
def forward(self, _x_list):
return NotImplementedError()
def backward(self, _grad_y_list):
return NotImplementedError()
Python
복사
2-1-1 [Function modified]
수정 내용을 확인하셨나요?
그러면 이를 활용해 클래스를 만들어봅시다.
Add입니다. add를 함수화 시키는 것도 잊지 마세요.
class Add(Function):
def forward(self, _x_list):
x0, x1 = _x_list
y = x0 + x1
return (y,)
def add(x):
return Add()(x)
Python
복사
2-1-2-1 [Add]
테스트입니다.
x_list = [Variable(numpy.array(2)), Variable(numpy.array(3))]
y_list = add(x_list)
y = y_list[0]
print(y._data)
# 5
Python
복사
2-1-2-2 [Add Example]
개선하기
사실 위처럼 매번 튜플화를 시키면 사용할 때 굉장히 귀찮습니다.
Tuple을 만들어서 전달하는 것이 아니라, 직접 인자를 전달하도록 합시다.
이를 위해선 Function이 수정되어야 합니다.
* 표를 붙임으로써 가변 인자를 받을 수 있습니다.
class Function:
def __call__(self, *_input_list):
x_list = [x._data for x in _input_list]
y_list = self.forward(*x_list)
if not isinstance(y_list, tuple):
y_list = (y_list, )
output_list = [Variable(as_array(y)) for y in y_list]
for output in output_list:
output.set_creator(self)
self._input_list = _input_list
self._output_list = output_list
return output_list if len(output_list) > 1 else output_list[0]
def forward(self, _x_list):
return NotImplementedError()
def backward(self, _grad_y_list):
return NotImplementedError()
Python
복사
2-2-1-1 [Variable Arguments: Function]
Add도 수정해주세요.
class Add(Function):
def forward(self, _x0, _x1):
y = _x0 + _x1
return y
def add(x0, x1):
return Add()(x0, x1)
Python
복사
2-2-1-2 [Variable Arguments: Add]
이제는 다음과 같이 결과를 볼 수 있습니다.
x0 = Variable(numpy.array(2))
x1 = Variable(numpy.array(3))
y = add(x0, x1)
print(y._data)
# 5
Python
복사
2-2-1-3 [Variable Arguments: Example]
가변 길이 인수: 역전파
덧셈(Add)의 역전파입니다.
출력에서 전해오는 미분값에 1을 곱하면 바로 입력 변수()의 미분이 됩니다.
즉 상류에서 오는 미분값을 그대로 흘려보냅니다.
class Add(Function):
def forward(self, _x0, _x1):
y = _x0 + _x1
return y
def backward(self, _grad_y):
return _grad_y, _grad_y
Python
복사
2-3-1 [Variable Arguments: Add Backward]
이에 맞춰 Variable도 수정되어야 합니다.
class Variable:
def __init__(self, _data):
if _data is not None:
if not isinstance(_data, numpy.ndarray):
raise TypeError("The type {} is not supported.".format(type(_data)))
self._data = _data
self._grad = None
self._creator = None
def set_creator(self, _func):
self._creator = _func
def backward(self):
if self._grad is None:
self._grad = numpy.ones_like(self._data)
funcs = [self._creator]
while funcs:
f = funcs.pop()
grad_y_list = [output._grad for output in f._output_list] #주석1
grad_x_list = f.backward(*grad_y_list) #주석2
if not isinstance(grad_x_list, tuple): #주석3
grad_x_list = (grad_x_list, )
for x, grad_x in zip(f._input_list, grad_x_list): #주석4
x._grad = grad_x
if x._creator is not None:
funcs.append(x._creator)
Python
복사
2-3-2 [Variable Arguments: Variable Backward]
•
주석1:
출력 변수인 output_list에 담겨있는 미분값들을 리스트에 담습니다.
•
주석2:
함수 f의 역전파를 호출합니다. 이 때 *을 통해 list unpack도 해줍니다.
•
주석3:
grad_x_list를 검사한 후 tuple화 시킵니다.
•
주석4:
역전파로 전달되는 미분값을 grad에 저장합니다.
여기에서 다음
마지막으로 Square 클래스도 위에 맞게 수정합니다.
class Square(Function):
def forward(self, _x):
return _x ** 2
def backward(self, _grad_y):
x = self._input_list[0]._data
return 2 * x * _grad_y
Python
복사
2-3-3 [Varaible Arguments: Square Backward]
그럼 마지막으로 사용 예제를 만들어 보세요.

, ,
다음 식을 DeZero를 이용하여 계산하도록 코드를 구성해 주세요.
결과물은 밑과 같습니다.
Code (답)
13.0
4.0
6.0
Python
복사
2-3-4-2 [Variable Arguments: Example Result]
같은 변수 반복 사용
이번 파트에서는 y = add(x, x)처럼 같은 변수를 여러번 사용할 때 발생하는 문제를 처리해보려 합니다.
x = Variable(numpy.array(2.0))
y = add(x, x)
print(y._data)
y.backward()
print(x._grad)
# 4.0
# 1.0
Python
복사
2-4-1 [Present]
현재에는 이렇게 동작합니다.
왜 이런 문제가 발생할까요?
이유는 바로 Variable 클래스에 있습니다.
def backward(self):
if self._grad is None:
self._grad = numpy.ones_like(self._data)
funcs = [self._creator]
while funcs:
f = funcs.pop()
grad_y_list = [output._grad for output in f._output_list] #주석1
grad_x_list = f.backward(*grad_y_list) #주석2
if not isinstance(grad_x_list, tuple): #주석3
grad_x_list = (grad_x_list, )
for x, grad_x in zip(f._input_list, grad_x_list): #주석4
x._grad = grad_x
if x._creator is not None:
funcs.append(x._creator)
Python
복사
2-4-2 [Variable - Problem]
중간에 highlight 처리 된 코드가 보이시나요? 바로 이 부분이 문제입니다.
출력(f.backward)에서 올라오는 grad_x를 그대로 저장하고 있습니다.
의 예시에서 보자면, 이므로 의 미분은 그대로 다 전파되어 인 2가 되어야 합니다.
그러나 지금은 덮어씌워지기 때문에 값이 1입니다.
이를 더 자세하기 위해 다음 코드를 x._grad 수정 시점 근처에다 적어주세요.
print("the NEW gradient value will be effected to x's gradient. grad_x :", grad_x)
Python
복사
2-4-3-1 [Debugging]
2-3-1 코드를 다시 한 번 실행해 보시면 출력한 디버깅 문장을 확인할 수 있습니다.
4.0
the NEW gradient value will be effected to x's gradient. grad_x : 1.0
the NEW gradient value will be effected to x's gradient. grad_x : 1.0
1.0
Python
복사
2-4-3-2 [Debugging Result]
grad_x가 두번 잘 들어오지만, 합산이 잘 안되는 걸 확인하실 수 있습니다.
해결법은 간단하죠! 들어오는 grad_x를 무결성 검사 후 반영시키면 됩니다.
highlight된 코드를 밑의 코드로 바꿔주세요.
if x._grad is None:
x._grad = grad_x
else:
x._grad = x._grad + grad_x
Python
복사
2-4-4 [Solution]
디버깅 문장을 지우고, 2-3-1 코드를 실행해보죠.
4.0
2.0
Python
복사
2-4-4-2 [Solution Result]
잘 되네요!
그러나 시련은 반복됩니다.
또 다른 문제 등장!
미분값 초기화 method!!
새로운 문제는 바로 같은 변수로 또 다른 동작을 수행할 경우입니다.
x = Variable(numpy.array(2.0))
y = add(x, x)
y.backward()
print(x._grad)
y = add(add(x, x), x)
y.backward()
print(x._grad)
# 2.0
# 5.0
Python
복사
2-4-5 [New Problem]
첫번째 실행 결과는 2.0이지만, 두 번째 결과가 5.0인 걸 확인하실 수 있습니다.
후 미분값은 2.0으로 맞는 결과이지만 두번째 의 결과는 3.0이어야 하니까요.
사실 add의 parameter가 두 개 밖에 안들어간다거나 등 자잘한 문제가 많이 보이지만,
이는 의도에서 약간 벗어나니 넘어갑시다.
필요하면 나중에 직접 추가하자구요!
책에서는 cleargrad만 추가하라고 되어 있었지만,
저는 좀 더 객체지향적인 코딩을 위해 다음과 같이 작성하였습니다.
class Variable:
# setter
def set_data(self, _data):
self._data = _data
def set_grad(self, _func):
self._grad = _func
def set_creator(self, _func):
self._creator = _func
# util methods
def clear_grad(self):
self.set_grad(None)
# constructor(init)
def __init__(self, _data):
if _data is not None:
if not isinstance(_data, numpy.ndarray):
raise TypeError("The type {} is not supported.".format(type(_data)))
self.set_data(_data)
self.set_creator(None)
self.set_grad(None)
# backward
def backward(self):
if self._grad is None:
self.set_grad(numpy.ones_like(self._data))
funcs = [self._creator]
while funcs:
f = funcs.pop()
grad_y_list = [output._grad for output in f._output_list] #주석1
grad_x_list = f.backward(*grad_y_list) #주석2
if not isinstance(grad_x_list, tuple): #주석3
grad_x_list = (grad_x_list, )
for x, grad_x in zip(f._input_list, grad_x_list): #주석4
if x._grad is None:
x._grad = grad_x
else:
x._grad = x._grad + grad_x
if x._creator is not None:
funcs.append(x._creator)
Python
복사
2-4-6 [Variable - more OOP]
멤버변수에 대해서 setter를 설정하였으며,
clear_grad는 외부에서 사용하는 원래 용도에 맞게
parameter 없이 직접 None을 세팅하는 방식으로 설정하였습니다.
또한 내부 멤버 변수를 건드리는 부분들을 다 setter를 사용하도록 하였습니다.
사실 제가 생각해서 “python에서 굳이?”라는 생각이 들기는 합니다.
접근제한자 등의 기능도 없는 python에서 이렇게 method를 분리하는 게 의미가 없긴 하죠.
뭔가 다른 해결방법을 생각해보자면 내부 변수를 다른 클래스에 만들어서 instance로 갖게 한 뒤 setter와 getter로만 가져올 수 있도록..?
안그래도 느린 파이썬에 그정도까지 할 필요는 없을 것 같다는 생각이 들었습니다.
자 그럼 이걸 사용해봅시다.
x = Variable(numpy.array(2.0))
y = add(x, x)
y.backward()
print(x._grad)
x.clear_grad()
y = add(add(x, x), x)
y.backward()
print(x._grad)
# 2.0
# 3.0
Python
복사
2-4-7 [Variable - more OOP example]
사실 이것도 사용자 입장에서 굉장히 불편하다고 생각합니다.
직접 clear 명령을 줘야 한다는 점을 뭔가 개선 가능할 것 같긴 한데 일단 넘어가겠습니다!
복잡한 계산 그래프

2-5-1 [Simple Calculation Graph]
현재까지 저희가 다른 계산 그래프는 위 이미지처럼 단순합니다.
하지만 이제부턴 이렇게 복잡한 그래프가 나옵니다.
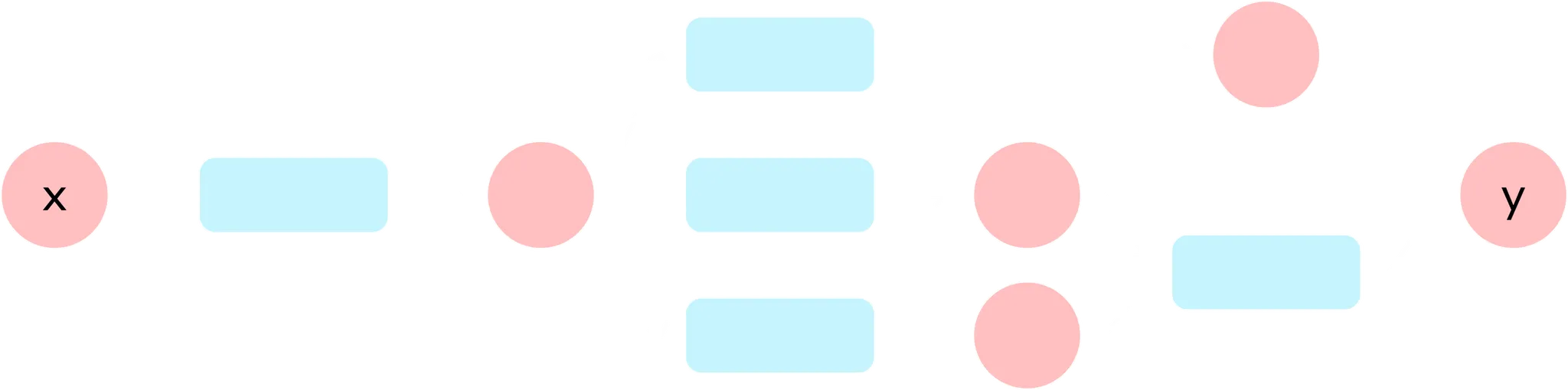
2-5-2 [Complex Calculation Graph]

2-5-3 [Calculation Graph - Branch]
위의 예시는 중간에 분기되었다가 돌아오는 계산 그래프입니다.
저희의 코드로는 아직 이 정도 수준도 실행이 불가능합니다.
주목할 점은 바로 변수 a입니다.
아까 보신 것처럼 같은 변수를 계속해서 사용하면 역전파 때는 출력에서 전파되는 미분값을 더해야 합니다.
따라서 a의 미분값 를 계산하려면 a의 출력쪽에서 전파하는 2개의 미분값을 알아야 합니다.
다음 그림은 미분값이 뒤에서부터 전달되가는 순서입니다.
(2와 3은 바뀌어도 괜찮습니다)
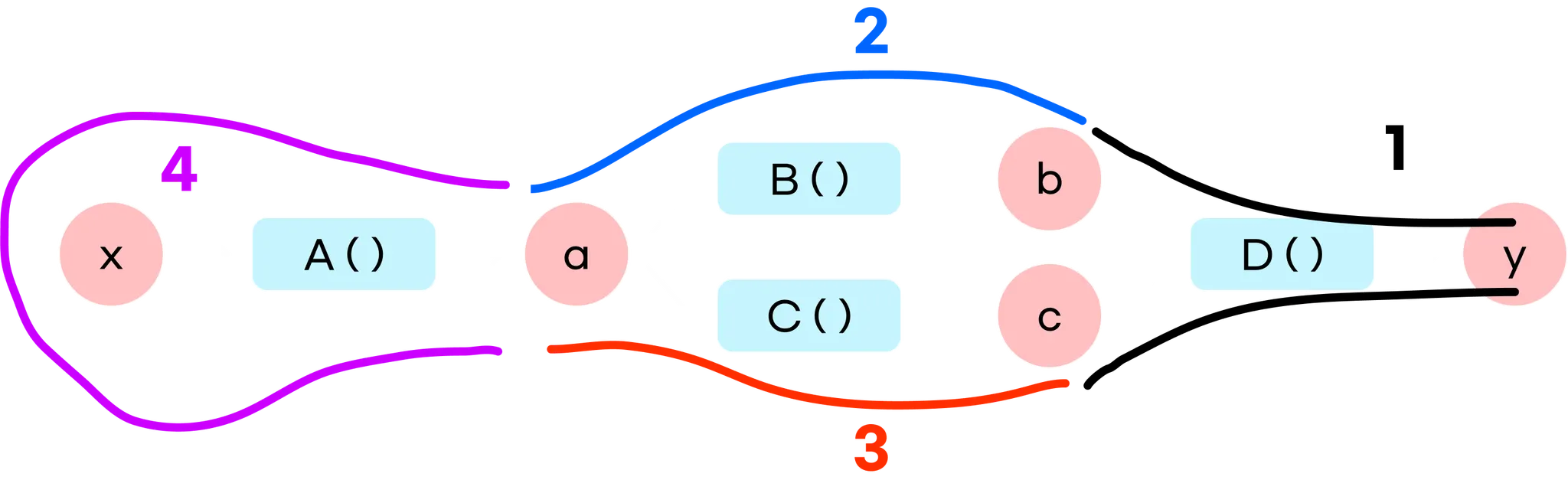
2-5-5 [Calculation Graph - Branch - Flow]
class Variable:
# setter
def set_data(self, _data):
self._data = _data
def set_grad(self, _func):
self._grad = _func
def set_creator(self, _func):
self._creator = _func
# util methods
def clear_grad(self):
self.set_grad(None)
# constructor(init)
def __init__(self, _data):
if _data is not None:
if not isinstance(_data, numpy.ndarray):
raise TypeError("The type {} is not supported.".format(type(_data)))
self.set_data(_data)
self.set_creator(None)
self.set_grad(None)
# backward
def backward(self):
if self._grad is None:
self.set_grad(numpy.ones_like(self._data))
f_list = [self._creator]
while f_list:
f = f_list.pop()
grad_y_list = [output._grad for output in f._output_list]
grad_x_list = f.backward(*grad_y_list)
if not isinstance(grad_x_list, tuple):
grad_x_list = (grad_x_list, )
for x, grad_x in zip(f._input_list, grad_x_list):
if x._grad is None:
x._grad = grad_x
else:
x._grad = x._grad + grad_x
if x._creator is not None:
f_list.append(x._creator)
Python
복사
2-5-6 [Variable Re]
현재 Variable 코드를 잘 봐주세요.
f_list를 처음 불러온 뒤, while문에 들어서면서 각 f들을 불러옵니다.
while문의 마지막을 보면, f_list에 처리할 함수들을 바로 추가하고 있습니다.
그 다음에 바로 다시 while의 위로 올라가며 그 함수를 리스트의 끝에서 꺼냅니다.
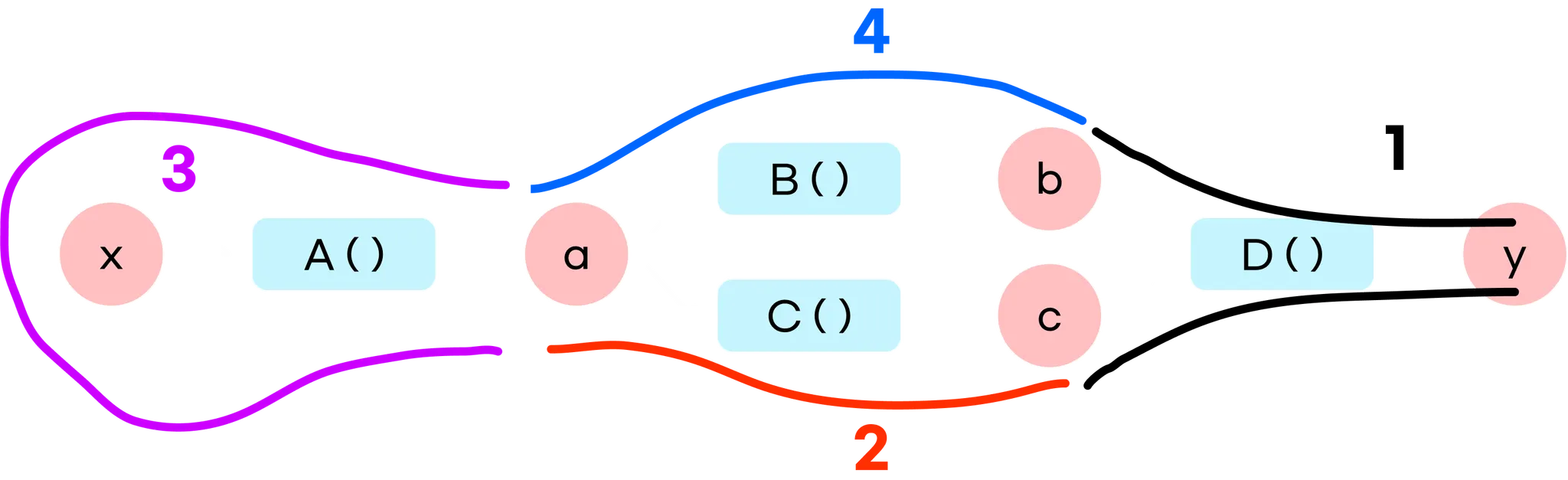
2-5-7 [Variable Current Flow]
이렇게 D, C, A, B, A 순으로 처리가 되는 문제가 있습니다.
C→A로 가는 흐름과 A가 중복처리가 된다는 것이 문제네요!
그리고 A의 역전파도 두번 일어납니다.
이를 해결하기 위해서는 f를 아무 생각 없이 마지막 원소를 꺼내오는 구조를 변경해야 합니다.
[B, A] 상태의 리스트가 있다고 했을 때 출력쪽에 더 가까운 B를 꺼내야 한다는 의미인거죠.
이런 우선순위를 해결하기 위해 적용할 수 있는 방법이 몇 개 있습니다.
•
위상정렬 Topological Sort
모르셔도 걱정하실 것 없습니다.
저희가 쓸 알고리즘은 아니니까요.
이 방법은 주어진 계산 그래프를 “분석”해서 알아내는 방법입니다.
노드의 연결 방법을 기초로 노드를 정렬합니다.
•
사실 저희는 더 쉬운 방법을 사용한 적이 있습니다.
바로 순전파 때 함수-변수 생성 과정에서 생기는 부모-자식 관계를 creator에 저장하고 있는 것입니다.
이런 방법을 통해 2-4-7을 x → A, a → B/C, b/c → D, y의 세대로 분류할 수 있습니다.
구현하기
class Variable:
# setter
def set_data(self, _data):
self._data = _data
def set_grad(self, _func):
self._grad = _func
def set_creator(self, _func):
self._creator = _func
def set_generation(self, _val):
self._generation = _val
# util methods
def clear_grad(self):
self.set_grad(None)
def modify_creator(self, _func):
self.set_creator(_func)
self.set_generation(self._generation + 1)
# constructor(init)
def __init__(self, _data):
if _data is not None:
if not isinstance(_data, numpy.ndarray):
raise TypeError("The type {} is not supported.".format(type(_data)))
self.set_data(_data)
self.modify_creator(None)
self.set_grad(None)
self.set_generation(0)
# backward
def backward(self):
if self._grad is None:
self.set_grad(numpy.ones_like(self._data))
f_list = [self._creator]
while f_list:
f = f_list.pop()
grad_y_list = [output._grad for output in f._output_list] #주석1
grad_x_list = f.backward(*grad_y_list) #주석2
if not isinstance(grad_x_list, tuple): #주석3
grad_x_list = (grad_x_list, )
for x, grad_x in zip(f._input_list, grad_x_list): #주석4
if x._grad is None:
x._grad = grad_x
else:
x._grad = x._grad + grad_x
if x._creator is not None:
f_list.append(x._creator)
Python
복사
2-6-1 [Variable - Generation]
Variable에 generation을 추가하였습니다.
기존 DeZero의 코드와 다르게 set_generation 메소드가 적용되었고, set_creator의 기능을 남기기 위해 modify_creator 메소드에 기존 set_creator와 generator의 증감 역할을 하는 기능까지 넣었습니다.
이에 맞게 다른 코드들도 수정해야함을 잊지 마세요.
class Function:
# setter
def set_input_list(self, _data):
self._input_list = _data
def set_output_list(self, _data):
self._output_list = _data
def set_generation(self, _data):
self._generation = _data
# call
def __call__(self, *_input_list):
x_list = [x._data for x in _input_list]
y_list = self.forward(*x_list)
if not isinstance(y_list, tuple):
y_list = (y_list, )
output_list = [Variable(as_array(y)) for y in y_list]
self.set_generation(max([x._generation for x in _input_list]))
for output in output_list:
output.modify_creator(self)
self.set_input_list(_input_list)
self.set_output_list(output_list)
return output_list if len(output_list) > 1 else output_list[0]
def forward(self, _x_list):
return NotImplementedError()
def backward(self, _grad_y_list):
return NotImplementedError()
Python
복사
2-6-2 [Function - Generation]
세대 순으로 꺼내기
다음 표는 2-4-7 이미지의 각 요소들의 세대를 정리한 것입니다.
요소 | 세대 |
함수를 세대 순으로 꺼내기 위해 Dummy DeZero를 이용해 보겠습니다.
generations = [2, 0, 1, 4, 2]
funcs = []
for g in generations:
f = Function()
f._generation = g
funcs.append(f)
print([f._generation for f in funcs])
funcs.sort(key=lambda x: x._generation)
print([f._generation for f in funcs])
f = funcs.pop()
print(f._generation)
# [2, 0, 1, 4, 2]
# [0, 1, 2, 2, 4]
# 4
Python
복사
2-6-3 [Generation Example]
Variable - backward
여기서는 앞의 설명대로 그냥 f_list에 넣지 않도록 추가하는 부분을 함수화하였습니다.
코드를 잘 확인해 보세요.
class Variable:
# setter
def set_data(self, _data):
self._data = _data
def set_grad(self, _func):
self._grad = _func
def set_creator(self, _func):
self._creator = _func
def set_generation(self, _val):
self._generation = _val
# util methods
def clear_grad(self):
self.set_grad(None)
def modify_creator(self, _func):
self.set_creator(_func)
self.set_generation(self._generation + 1)
# constructor(init)
def __init__(self, _data):
if _data is not None:
if not isinstance(_data, numpy.ndarray):
raise TypeError("The type {} is not supported.".format(type(_data)))
self.set_data(_data)
self.modify_creator(None)
self.set_grad(None)
self.set_generation(0)
# backward
def backward(self):
if self._grad is None:
self.set_grad(numpy.ones_like(self._data))
f_list = []
seen_set = []
def add_func(_func):
if _func not in seen_set:
f_list.append(_func)
seen_set.add(_func)
f_list.sort(key=lambda x: x._generation)
add_func(self._creator)
while f_list:
f = f_list.pop()
grad_y_list = [output._grad for output in f._output_list] #주석1
grad_x_list = f.backward(*grad_y_list) #주석2
if not isinstance(grad_x_list, tuple): #주석3
grad_x_list = (grad_x_list, )
for x, grad_x in zip(f._input_list, grad_x_list): #주석4
if x._grad is None:
x._grad = grad_x
else:
x._grad = x._grad + grad_x
if x._creator is not None:
add_func(x._creator)
Python
복사
2-6-4 [Variable - add func]
Check
확인용 코드입니다.
x = Variable(numpy.array(2.0))
a = square(x)
y = add(square(a), square(a))
y.backward()
print(y._data)
print(x._grad)
# 32.0
# 64.0
Python
복사
2-6-5 [Variable - Check]
~ 중간 정리 ~
잠깐만!
지금까지 실행하다가 저는 코드가 다 꼬여버려서 실행이 안되는 대참사가 발생해버렸습니다.
좀 더 자세히 설명하자면, 위의 Check 결과 Function에서도 Variable에서도 generation이 존재하지 않는다는 에러가 발생하더라구요.
코드를 쭉 정리해 본 결과 실행 중간중간에 [모든 셀의 출력 지우기] 기능을 수행하지 않아 에러가 발생한 것 같습니다.
개대밑에 중간 정리 코드를 올려놓을테니 꼭 정리하면서 진행하는거 잊지 마세요!
메모리 관리와 순환 참조
이번 파트에서는 DeZero의 성능 측면을 강화할 예정입니다.
처리 속도와 메모리 속도를 올리는 내용 중심입니다.
참고로, 이 내용들은 CPython을 기준으로 합니다.
메모리 관리
Python에서는 미사용 객체를 자동으로 삭제합니다.
그러나 이 기능이 있다고 해도, 메모리 누수와 메모리 부족 문제가 100% 해결되는 것은 아닙니다.
그럼 파이썬은 어떻게 메모리를 관리하고 있을까요?
두 가지 방식이 있습니다.
1.
참조 카운터
참조(reference)의 수를 세는 방법
2.
Garbege Collection (GC)
세대(generation)을 기준으로 불필요한 객체를 회수하는 방법
참조 카운터 방식의 메모리 관리
파이썬 메모리 관리의 기본은 참조 카운트입니다.
이 방식은 간단하며 빠릅니다!
모든 객체의 참조 카운트를 0으로 놓고 생성한 뒤, 다른 객체가 참조할 때마다 1씩 증가하며 참조가 끊길 때마다 1씩 감소하다 0까지 줄어들면 파이썬 인터프리터가 회수합니다.
이런 방식으로 필요 없어지면 삭제가 되는 것입니다.
참고로, 참조 카운트가 증가하는 경우는 다음과 같습니다.
•
대입 연산자 사용
•
함수에 인수로 전달
•
컨테이너 타입 개체(list, tuple, class)등에 추가할 때
코드 예시입니다. (실제 동작하지 않습니다!)
# 실행하면 에러가 나는게 맞습니다!
# It is correct that if you see the error with this codebox!
class obj:
pass
def f(x):
print(x)
a = obj() # 참조 카운트: 1: 변수에 대입
f(a) # 참조 카운트: 2: 함수에 대입
# 참조 카운트: 1: 함수에서 나와서 다시 1
a = None # 참조 카운트: 0: 대입 해제
Python
복사
2-7-1 [참조 카운트 예시코드]
위 코드처럼, 참조 카운트 방식은 간단합니다.
그리고 이 방식을 이용하여 많은 메모리 문제를 해결할 수 있습니다.
a = obj()
b = obj()
c = obj()
a.b = b
b.c = c
a = b = c = None
Python
복사
2-7-2 [참조 카운트 예시코드2]
먼저 a, b, c라는 세 객체를 생성했습니다.
a가 b를, b가 c를 참조하는 관계입니다.
여기서 순차적으로 참조카운트가 모두 0이 되어 전부 삭제됩니다.
그러나 이렇게 좋은 참조 카운트도 단점이 있는데요, 바로 순환참조를 해결하지 못한다는 점입니다.
순환 참조
다음은 순환참조의 이해를 돕는 코드입니다.
a = obj()
b = obj()
c = obj()
a.b = b
b.c = c
c.a = a
a = b = c = None
Python
복사
2-7-3 [순환 참조 예시코드1]
앞의 코드와 거의 일치해 보이지만, c→a로의 참조가 추가됬습ㄴ디ㅏ.
이렇게 되면 서로 원을 그리며 서로가 서로를 참조하게 되고, 각각의 참조 카운트는 모두 1이 됩니다.
그러나 사용자는 이 중 어떤 것의 값에도 접근할 수 없고, 불필요한 객체가 되버립니다.
또한 a = b = c = None을 실행한다 하더라도 순환 참조의 카운트가 줄어들지 않습니다.
그래서 등작한 것이 바로 GGC(Generational Garbage Collection)
GC(GGC)는 참조 카운트보다 영리하게 불필요한 객체르 찾아냅니다.
이 방식은 “메모리가 부족할 때마다 자동으로 호출”됩니다.
물론, gc.collect() 명령어로 직접 실행할 수도 있습니다.
순환 참조 등은 메모리/속도에 영향을 끼칩니다.
특히 딥러닝은 많은 연산량을 필요로 하며, 이런 문제가 생기지 않도록 하는 것이 굉장히 중요합니다.
그러나 저희 코드를 잘 보면 이미 순환 참조가 있습니다.
바로 다음 그림에서 나오는데요,
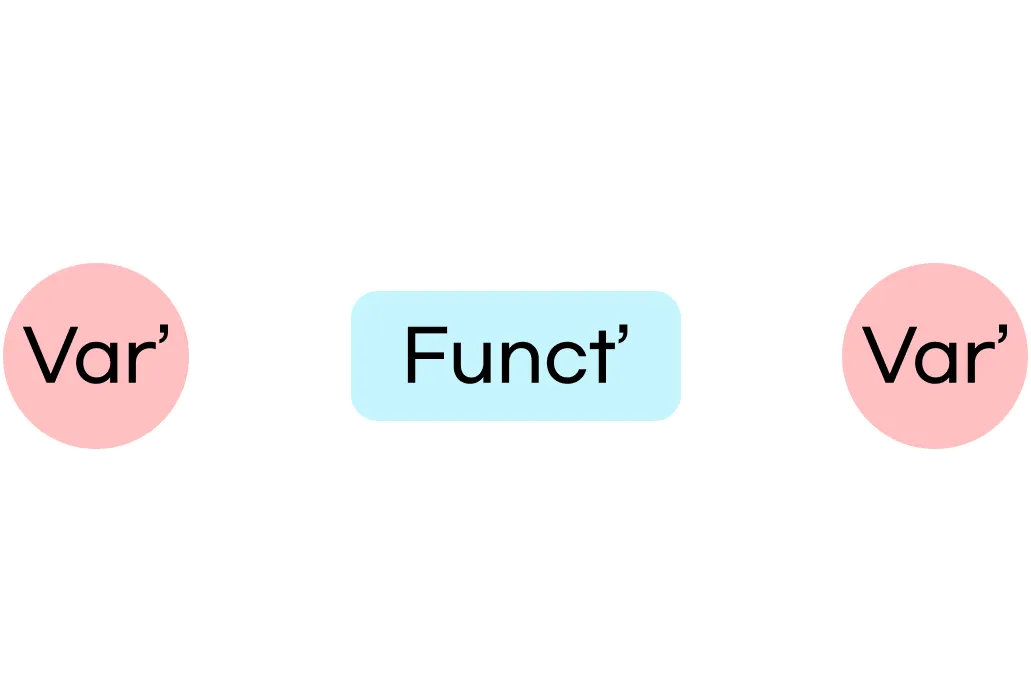
2-7-4 [순환 참조]
Function 인스턴스는 두 개의 Variable을 참조합니다. 바로 input과 output이죠.
그리고 output Variable 인스터스는 창조자인 Function 인스터스를 참조합니다.
이렇게 순환 참조 관계를 만들어냅니다.
다행히도, 이를 해결하기 위한 표준 파이썬 모듈이 있습니다.
weakref 모듈
Python에서는 weakref.ref를 사용해 약한 참조 weak refernece를 만들 수 있습니다.
import weakref
import numpy
a = numpy.array([1, 2, 3])
b = weakref.ref(a)
print(b)
print(b())
a = None
print(b)
# <weakref at 0x1104540e0; to 'numpy.ndarray' at 0x1044eea90>
# [1 2 3]
# <weakref at 0x1104540e0; dead>
Python
복사
2-7-5 [weakref.ref]
numpy array를 예시로 해봤습니다.
a는 일반적인 참조, b는 약한 참조입니다.
여기서 b를 출력해보면 numpy array를 가르키는 약한 참조임을 확인할 수 있습니다.
이 구조를 DeZero에도 도입해보겠습니다.
class Function:
# # setter
def set_input_list(self, _data):
self._input_list = _data
def set_output_list(self, _data):
self._output_list = _data
def set_generation(self, _data):
self._generation = _data
# call
def __call__(self, *_input_list):
x_list = [x._data for x in _input_list]
y_list = self.forward(*x_list)
if not isinstance(y_list, tuple):
y_list = (y_list, )
output_list = [Variable(as_array(y)) for y in y_list]
self.set_generation(max([x._generation for x in _input_list]))
for output in output_list:
output.modify_creator(self)
self.set_input_list(_input_list)
self.set_output_list([weakref.ref(output) for output in output_list])
return output_list if len(output_list) > 1 else output_list[0]
def forward(self, _x_list):
return NotImplementedError()
def backward(self, _grad_y_list):
return NotImplementedError()
Python
복사
2-7-6 [weakref: Function]
class Variable:
# setter
def set_data(self, _data):
self._data = _data
def set_grad(self, _func):
self._grad = _func
def set_creator(self, _func):
self._creator = _func
def set_generation(self, _val):
self._generation = _val
# util methods
def clear_grad(self):
self.set_grad(None)
def modify_creator(self, _func):
self.set_creator(_func)
self.set_generation(self._generation + 1)
# constructor(init)
def __init__(self, _data):
if _data is not None:
if not isinstance(_data, numpy.ndarray):
raise TypeError("The type {} is not supported.".format(type(_data)))
self.set_generation(0)
self.set_data(_data)
self.modify_creator(None)
self.set_grad(None)
# backward
def backward(self):
if self._grad is None:
self.set_grad(numpy.ones_like(self._data))
f_list = []
seen_set = set()
def add_func(_func):
if _func not in seen_set:
f_list.append(_func)
seen_set.add(_func)
f_list.sort(key=lambda x: x._generation)
add_func(self._creator)
while f_list:
f = f_list.pop()
grad_y_list = [output()._grad for output in f._output_list] #주석1
grad_x_list = f.backward(*grad_y_list) #주석2
if not isinstance(grad_x_list, tuple): #주석3
grad_x_list = (grad_x_list, )
for x, grad_x in zip(f._input_list, grad_x_list): #주석4
if x._grad is None:
x.set_grad(grad_x)
else:
x.set_grad(x._grad + grad_x)
if x._creator is not None:
add_func(x._creator)
Python
복사
2-7-7 [weakref: Variable]
동작 확인
for i in range(10):
x = Variable(numpy.random.randn(10000))
y = square(square(square(x)))
Python
복사
2-7-8 [동작 확인]
~ 중간 정리 ~
잠깐만!
메모리 절약하기
이전 단계에서는 DeZero의 메모리 사용 자체를 줄이기 위한 방안을 도입했었습니다.
이번에는 불필요한 메모리 사용을 줄이기 위한 방법 두 가지를 도입해보겠습니다.
•
첫 번째는 불필요한 미분값 자체를 보관하지 않고 즉시 삭제하는 것입니다.
•
두 번째는 역전파가 필요없는 모드를 만드는 것입니다.
필요없는 미분값 삭제하기
필요없는 미분값은 ㅁㅁㅇㅁㄴㅇㅂㅈㄷㅁㅊㅋㅊㅋㅌㅊ